Our everyday scientific and educational work relies heavily on hardware, software, and, in modern times, cloud services. The equipment that we will mention below is specific to our group; common services used by university and/or faculty employees will not be specifically mentioned here.
Another week gone by and it's saturday morning again.
We are in final freeze for Fedora 42 right now, so things have been
a bit quieter as folks (hopefully) are focusing on quashing release
blocking bugs, but there was still a lot going on.
Unsigned packages in images (again)
We had some rawhide/branched images show up again with unsigned packages.
This is due to my upgrading koji packages and dropping a patch we had
that tells it to never use the buildroot repo for packages (unsigned)
when making images, and to instead use the compose repo for packages.
I thought this was fixed upstream, but it was not. So, the fix for now
was a quick patch and update of koji. I need to talk to koji upstream
about a longer term fix, or perhaps the fix is better in pungi.
In any case, it should be fixed now.
Amusing idempotentness issue
In general, we try and make sure our ansible playbooks are idempotent.
That is, that if you run it once, it puts things in the desiired state,
and if you run it again (or as many times as you want), it shouldn't change
anything at all, as the thing is in the desired state.
There are all sorts of reasons why this doesn't happen, sometimes
easy to fix and sometimes more difficult. We do run a daily ansible-playbook
run over all our playbooks with '--check --diff', that is... check what
(if anything) changed and what it was.
I noticed on this report that all our builders were showing a change
in the task that installs required packages. On looking more closely,
it turns out the playbook was downgrading linux-firmware every run,
and dnf-automatic was upgrading it (because the new one was marked as
a security update). This was due to us specifying "kernel-firmware" as
the package name, but only the older linux-firmware package provided
that name, not the new one. Switching that to the new/correct 'linux-firmware'
cleared up the problem.
AI scraper update
I blocked a ton of networks last week, but then I spent some time to look
more closely at what they were scraping. Turns out there were 2 mirrors
of projects (one linux kernel and one git ) that the scrapers were really
really interested in. Since those mirrors had 0 commits or updates in the
last 5 years since they were initially created, I just made those both
403 in apache and... the load is really dramatically better. Almost
back to normal. I have no idea why they wanted to crawl those old copies
of things already available elsewhere, and I doubt this will last,
but for now this gives us a bit of time to explore other options
(because I am sure they will be back).
Datacenter Move
I'm going to likely be sending out a devel-announce / community blog post
next week, but for anyone who is reading this a sneak preview:
We are hopfully going to gain at least some network on our new hardware
around april 16th or so. This will allow us to get in and configure
firmware, decide setup plans and start installing enough machines to
bootstrap things up.
The plan currently is still to do the 'switcharoo' (as I am calling it)
on the week of June 16th. Thats the week after devconf.cz and two weeks
after flock.
For Fedora linux users, there shouldn't be much to notice. Mirrorlists will
all keep working, websites, etc should keep going fine. pagure.io will not
be directly affected (it's moving later in the year).
For Fedora contributors, monday and tuesday we plan to "move" the bulk
of applications and services. I would suggest just trying to avoid doing
much on those days as services may be moving around or broken in various ways.
Starting wed, we hope to make sure everything is switched and fix problems
or issues. In some ideal world, we could just relax then, but if not,
Thursday and Friday will continue stablization work.
The following week, the newest of the old machines in our current datacenter
will be shipped to the new one. We will bring those up and add capacity
on them (many of them will add openqa or builder resources).
That is at least the plan currently.
Spam on matrix
There's been another round of spam on matrix this last week. It's not just Fedora
thats being hit, but many other communities that are on Matrix. It's also not
like older communications channels (IRC) didn't have spammers on them at times
in the past either. The particularly disturbing part on the matrix end is that
the spammers post _very_ distirbing images. So, if you happen to look before they
get redacted/deleted it's quite shocking (which is of course what the spammer wants).
We have (for a long while) a bot in place and it redacts things pretty quickly
usually, but then you have sometimes a lag in matrix federation, so folks on
some servers still see the images until their server gets the redaction events.
There are various ideas floated to make this better, but due to the way matrix
works, along with wanting to allow new folks to ask questions/interact, there
is not any simple answers. It may take some adjustments to the matrix protocol.
If you are affected by this spam, you may want to set your client to not 'preview'
images (so it won't load them until you click on them), and be patient as
our bot bans/kicks/redacts offenders.
Fedora test days are events where anyone can help make certain that changes in Fedora Linux work well in an upcoming release. Fedora community members often participate, and the general public is also welcome at these events. If you’ve never contributed to Fedora Linux before, this is the perfect way to get started.
There are two overlapping test periods in the coming week.
Monday 07 April through Friday, April 11, focuses on testing Fedora IoT .
Tuesday 08 April through Tuesday, April 15, focuses on testing the GNOME 48 desktop and core applications.
Fedora IoT
For this test week, the focus is all-around; test all the bits that come in a Fedora IoT release as well as validate different hardware. This includes:
Basic installation to different media
Installing in a VM
rpm-ostree upgrades, layering, rebasing
Basic container manipulation with Podman.
We welcome all different types of hardware, but have a specific list of target hardware for convenience. This test week will occur Monday 07 April through Friday 11 April.
GNOME 48 Test Week
The Desktop/Workstation team is working on final integration for GNOME 48. This version was recently released, and will arrive soon in Fedora Linux. As a result, the Fedora desktop and Quality teams are organizing a test week from Tuesday, April 08, 2025 to Tuesday, April 15, 2025. The wiki page in this article contains links to the test images you’ll need to participate.
How does a test week work?
A test week is an event where anyone can help ensure changes in Fedora Linux work well in an upcoming release. Fedora community members often participate, and everyone is welcome at these events. If you’ve never contributed before, this is a perfect way to get started.
To contribute, you only need to be able to do the following things:
Download the test materials, which include some large files.
Read and follow the directions step by step.
Happy testing and we hope to see you at one (or more!) of the test day events.
This is a weekly report from the I&R (Infrastructure & Release Engineering) Team. We provide you both infographic and text version of the weekly report. If you just want to quickly look at what we did, just look at the infographic. If you are interested in more in depth details look below the infographic.
Week: 31st March – 4th April 2025
Infrastructure & Release Engineering
The purpose of this team is to take care of day to day business regarding CentOS and Fedora Infrastructure and Fedora release engineering work. It’s responsible for services running in Fedora and CentOS infrastructure and preparing things for the new Fedora release (mirrors, mass branching, new namespaces etc.). List of planned/in-progress issues
Fedora test days are events where anyone can help make certain that changes in Fedora Linux work well in an upcoming release. Fedora community members often participate, and the public is welcome at these events. If you’ve never contributed to Fedora before, this is a perfect way to get started.
There are two test periods occurring in the coming days:
Sunday April 06 through April 12, is to test Kernel 6.14
Monday April 07 through April 11, is to test Accessiblity (a11y)
Kernel 6.14 Test Week
The kernel team is working on final integration for Linux kernel 6.14. This recently released kernel version will arrive soon in Fedora Linux. As a result, the Fedora Linux kernel and QA teams have organized a test week from Sunday, April 06, 2025 to Sunday, April 12, 2025.
The wiki page contains links to the test images you’ll need to participate. The results can be submitted in the test day app.
Accessibility Test Week
In the spirit of fostering a diverse and inclusive community and in the spirit of staying true to EAA, Fedora is proud to announce its upcoming Accessibility (a11y) Test Week. It aims to ensure that our software is accessible to everyone, including individuals with disabilities. This initiative is not just about refining software but about affirming Fedora’s commitment to accessibility and inclusivity.
Accessibility Test Week is an opportunity for testers, developers, and users to contribute to the betterment of Fedora by ensuring that our latest features and software in GNOME are accessible. Testing plays a crucial role in the development cycle, helping to identify and rectify accessibility barriers that might prevent users from fully utilizing Fedora. It is an intensive, collaborative effort to push the boundaries of inclusivity in technology.
To participate, you’ll need access to Fedora Pre-release (F42) with the latest updates installed. Visit our Accessibility Test Week page for detailed instructions and support. The reports and findings can be shared here.
How do test days work?
To contribute, you only need to be able to download test materials (which include some large files) and then read and follow directions step by step.
Detailed information about all the test days is available on the wiki pages mentioned above. If you’re available on or around the days of the events, please do some testing and report your results. All the test day pages receive some final touches which complete about 24 hrs before the test day begins. We urge you to be patient about resources that are, in most cases, uploaded hours before the test day starts.
Come and test with us to make the upcoming Fedora Linux 42 even better
I got a new laptop (a Lenovo Thinkpad X1 Carbon Gen 12, more on that later) and as always with new pets, it needed a name.
My naming scheme is roughly "short japanese words that somehow relate to the machine".
The current (other) machines at home are (not all really in use):
Thinkpad X1 Carbon G9 - tanso (炭素), means carbon
Thinkpad T480s - yatsu (八), means 8, as it's a T480s
Thinkpad X201s - nana (七), means 7, as it was my first i7 CPU
Thinkpad X61t - obon (御盆), means tray, which in German is "Tablett" and is close to "tablet"
Thinkpad X300 - atae (与え) means gift, as it was given to me at a very low price, almost a gift
Thinkstation P410 - kangae (考え), means thinking, and well, it's a Thinkstation
self-built homeserver - sai (さい), means dice, which in German is "Würfel", which is the same as cube, and the machine used to have an almost cubic case
Raspberry Pi 4 - aita (開いた), means open, it's running OpenWRT
Sun Netra T1 - nisshoku (日食), means solar eclipse
Apple iBook G4 13 - ringo (林檎), means apple
Then, I happen to rent a few servers:
ippai (一杯), means "a cup full", the VM is hosted at "netcup.de"
genshi (原子), means "atom", the machine has an Atom CPU
shokki (織機), means loom, which in German is Webstuhl or Webmaschine, and it's the webserver
I also had machines in the past, that are no longer with me:
Thinkpad X220 - rodo (労働) means work, my first work laptop
Thinkpad X31 - chiisai (小さい) means small, my first X series
Thinkpad Z61m - shinkupaddo (シンクパッド) means Thinkpad, my first Thinkpad
And also servers from the past:
chikara (力) means power, as it was a rather powerful (for that time) Xeon server
hozen (保全), means preservation, it was a backup host
So, what shall I call the new one?
It will be "juuni" (十二), which means 12.
Creative, huh?
The new iOS 18.4 has an unbelievably wonderful, unprecedented — and somewhat hidden — feature.
Ambient Music!
There are four buttons you can activate in the Control Center that provide endless ambient music in four styles and for four purposes:
Relaxation
Focus & Productivity
Well-being
Sleep
The compositions and arrangements are of high quality and very satisfying. They are purely instrumental, with little melodic variation but rich in textures, sound effects, rhythm, and sound design. If voices appear — rarely — they are only used to add texture, without words.
I am an avid listener of ambient music and use it to block out external noise, enter my inner world, focus, relax, find inspiration, and fall asleep. Collections like Buddha-Bar, Café del Mar, Le Café Abstrait, and their curators have been in my ears for many years, introducing me to many artists I now love and follow. Unlike Apple’s new Ambient Music, these collections also include more ethnic styles.
But there’s something obscure and noteworthy about Apple Ambient Music. There are no song titles, no artist credits, no album covers. Music identifiers like Shazam don’t recognize these tracks—I’ve tried multiple times. I haven’t noticed any repeated songs, and they all last around three minutes. It’s as if they were commissioned for this purpose, following specific rules. I also haven’t found any Apple page describing the technology, the source of the collection, or how the curation of the four playlists works.
This leads me to believe the music is dynamically generated (both composed and performed) by artificial intelligence or some algorithm. The fact that the tracks have little melodic richness — melody being the most valuable, human, and difficult-to-create musical feature — supports this hypothesis. A well-built library of textures and sound effects, combined with fine-tuned algorithms, could make this possible.
But this raises a very serious ethical question, especially when the feature is made so accessible and mainstream. Could AI replace composers, musicians, and sound engineers in some musical styles? Could this explain why Apple isn’t making a big deal out of this feature, despite it deserving the spotlight?
Apple Ambient Music is now part of my listening repertoire.
A change in Fedora’s thunderbird RPM package a few months ago led to some issues with the Fedora Flatpak thereof, not only in Software/Discover but also in desktop usage, such as windows not being associated with their desktop icon. For instance, in KDE Plasma, a generic Wayland icon would be shown on the Task Manager bar even if the Thunderbird desktop menu entry was pinned.
I have taken the Fedora 42 update going stable tonight as an opportunity to fix that, but there are caveats. Users should get upgraded to the new name automatically, but when starting the app afterwards, it will look like you need to start over configuring your email accounts and so on. However, with a little manual intervention, this can be avoided.
If you have already reconfigured your accounts and are happy with the results (just not with the effort involved), then there is nothing more to do except to understand what happened and why it was ultimately necessary. Unfortunately we have no reliable way of letting users know about changes such as this.
Otherwise, if you have started Thunderbird after the upgrade and seen this but have not done anything significant afterwards, then this should be recoverable. Furthermore, if you have upgraded but have not yet started the app since, you can avoid this entirely, and step 2 below might not apply to you.
First, verify that the data from your previous usage is still intact:
find ~/.var/app/org.mozilla.Thunderbird/.thunderbird | less
If this shows a long list of files, and you have not yet done anything significant with the app after the “reset”, then you can proceed by removing the (very little) data from the new app name:
Hello everyone! Current Fedora Project Leader Matthew Miller here, with some exciting news!
A little while ago, I announced that it’s time for a change of hats. I’m going to be moving on to new things (still close to Fedora, of course). Today, I’m happy to announce that we’ve selected my successor: long-time Fedora friend Jef Spaleta.
Some of you may remember Jef’s passionate voice in the early Fedora community. He got involved all the way back in the days of fedora.us, before Red Hat got involved. Jef served on the Fedora Board from July 2007 through the end of 2008. This was the critical time after Fedora Extras and Fedora Core merged into one Fedora Linux where, with the launch of the “Features” process, Fedora became a truly community-led project.
Of course, things have changed a little around here since then. The Council replaced the Board, the Features process has changed (to “Changes“, of course), and … a few other things. Jef has been busy with various day jobs, but has always kept up with Fedora. I’m glad we’re now able to let him give his full attention to the next years of Fedora success.
Jef starts full-time at Red Hat in May. Then, after a few weeks for orientation, I’ll officially pass the torch at Flock in the beginning of June. Please join me in welcoming him back into the thick of things in Fedora-land in the Fedora Discussion thread for this post.
Speaking of Flock (our annual contributor conference)… we’re getting the final schedule lined up! We have an excellent slate of talks and speakers. Perhaps even more importantly, we have some of the best Fedora swag ever made. If you can, join us from June 5–8. Find more information, including registration links, on the Flock website. Prague is a great city, and particularly lovely in June, so if you’ve been looking for an excuse to visit, this is it!
Oh, and one more thing… if you’re really into curling, Jef will be very happy to talk to you about it!
This article is a tutorial on using UV to enhance or improve your Python work flow.
If you work with Python you most likely have used one or all of the following tools:
Pip to install packages or pipx to install them on virtual environments.
Anaconda to install packages, custom Python versions and manage dependencies
Poetry (and pipx), to manage your Python project and packaging.
Why do you need another tool to manage your Python packaging or install your favorite Python tools? For me, using uv was a decision based on the following features:
Simplicity: uv can handle all the tasks for packaging or installing tools with a very easy-to-use CLI.
Improved dependency management: When there are conflicts, the tool does a great job explaining what went wrong.
Speed: If you ever used Anaconda to install multiple dependencies like PyTorch, Ansible, Pandas, etc. you will appreciate how fast uv can do this.
Easy to install: No third-party dependencies to install, comes with batteries included (this is demonstrated in the next section).
Documentation: Yes, the online documentation is easy to follow and clear. No need to have a master degree in the occult to learn how to use the tool.
Now let’s be clear from the beginning, there is no one-size-fits-all tool that fixes all the issues with Python workflows. Here, I will try to show you why it may make sense for you to try uv and switch.
You will need a few things to follow this tutorial:
A Linux installation: I use Fedora but any other distribution will work pretty much the same.
An Internet connection, to download uv from their website.
Be familiar with pip and virtual environments: This is optional but it helps if you have installed a Python package before.
Python programming experience: We will not code much here, but knowing about Python modules and how to package a project using pyproject.toml with frameworks like setuptools will make it easier to follow.
Optionally, elevated privileges (SUDO), if you want to install binaries system-wide (like RPMS).
Let’s start by installing uv, if you haven’t done so already.
Installing UV
If you have a Linux installation you can install uv like this:
# The installer has options and an unattended installation mode, won't cover that here
curl -LsSf https://astral.sh/uv/install.sh | sh
Using an RPM? Fedora lists several packages since version 40. So there you can do something like this:
# Fedora RPM is slightly behind the latest version but it does the job
sudo dnf install -y uv
Or make yourself an RPM using the statically compiled binaries from Astral and a little help from Podman and fpm:
josevnz@dmaf5 docs]$ podman run --mount type=bind,src=$HOME/tmp,target=/mnt/result --rm --privileged --interactive --tty fedora:37 bash
[root@a9e9dc561788 /]# gem install --user-install fpm
...
[root@a9e9dc561788 /]# curl --location --fail --remote-name https://github.com/astral-sh/uv/releases/download/0.6.9/uv-x86_64-unknown-linux-gnu.tar.gz
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
0 0 0 0 0 0 0 0 --:--:-- --:--:-- --:--:-- 0
100 15.8M 100 15.8M 0 0 8871k 0 0:00:01 0:00:01 --:--:-- 11.1M
[root@a9e9dc561788 /]# fpm -t rpm -s tar --name uv --rpm-autoreq --rpm-os linux --rpm-summary 'An extremely fast Python package and project manager, written in Rust.' --license 'Apache 2.0' --version v0.6.9 --depends bash --maintainer 'Jose Vicente Nunez <kodegeek.com@protonmail.com>' --url https://github.com/astral-sh/uv uv-x86_64-unknown-linux-gnu.tar.gz
Created package {:path=>"uv-v0.6.9-1.x86_64.rpm"}
mv uv-v0.6.9-1.x86_64.rpm /mnt/result/
# exit the container
exit
You can then install it on /usr/local, using --prefix:
sudo -i
[root@a9e9dc561788 /]# rpm --force --prefix /usr/local -ihv /mnt/result/uv-v0.6.9-1.x86_64.rpm
Verifying... ################################# [100%]
Preparing... ################################# [100%]
Updating / installing...
1:uv-v0.6.9-1 ################################# [100%]
[root@a9e9dc561788 /]# rpm -qil uv-v0.6.9-1
Name : uv
Version : v0.6.9
Release : 1
Architecture: x86_64
Install Date: Sat Mar 22 23:32:49 2025
Group : default
Size : 40524181
License : Apache 2.0
Signature : (none)
Source RPM : uv-v0.6.9-1.src.rpm
Build Date : Sat Mar 22 23:28:48 2025
Build Host : a9e9dc561788
Relocations : /
Packager : Jose Vicente Nunez <kodegeek.com@protonmail.com>
Vendor : none
URL : https://github.com/astral-sh/uv
Summary : An extremely fast Python package and project manager, written in Rust.
Description :
no description given
/usr/local/usr/lib/.build-id
/usr/local/usr/lib/.build-id/a1
/usr/local/usr/lib/.build-id/a1/8ee308344b9bd07a1e3bb79a26cbb47ca1b8e0
/usr/local/usr/lib/.build-id/e9
/usr/local/usr/lib/.build-id/e9/4f273a318a0946893ee81326603b746f4ffee1
/usr/local/uv-x86_64-unknown-linux-gnu/uv
/usr/local/uv-x86_64-unknown-linux-gnu/uvx
Again, you have several choices.
Now it is time to move to the next section and see what uv can do to make Python workflows faster.
Using UV to run everyday tools like Ansible, Glances, Autopep8
One of the best things about uv is that you can download and install tools on your account with less typing.
One of my favorite monitoring tools, glances, can be installed with pip on the user account:
pip install --user glances
glances
But that will pollute my Python user installation with glances dependencies. So the best next thing is to isolate it on a virtual environment:
You can see now where this is going. Instead, I could do the following with uv:
uv tool run glances
That is a single line to run and install glances. This creates a temporary environment which can be discarded once we’re done with the tool.
Let me show you the equivalent command, it is called uvx:
uvx --from glances glances
If the command and the distribution match then we can skip explicitly where it comes ‘–from’:
uvx glances
Less typing, uv created a virtual environment for me and downloaded glances there. Now say that I want to use a different Python, version3.12, to run it:
uvx --from glances --python 3.12 glances
If you call this command again, uvx will re-use the virtual environment it created, using the Python interpreter of your choice.
You just saw how uv allows you to install custom Python interpreters. This topic is covered in a bit more detail in the following section.
Is it a good idea to install custom Python interpreters?
Letting Developers and DevOps install custom Python interpreters can be a time-saver, given that no elevated privileges are required and the hassle of making an RPM to distribute a new Python is gone.
Where was it installed? Let’s search for it and run it:
# It is not the system python3 [josevnz@dmaf5 ~]$ which python3 /usr/bin/python3
# And not in the default PATH [josevnz@dmaf5 ~]$ which python3.13 /usr/bin/which: no python3.13 in (/home/josevnz/.cargo/bin:/home/josevnz/.local/bin:/home/josevnz/bin:/usr/local/bin:/usr/local/sbin:/usr/bin:/usr/sbin:/home/josevnz/.local/share/JetBrains/Toolbox/scripts)
# Ah it is inside /home/josevnz/.local/share/uv/python, Let's run it: [josevnz@dmaf5 ~]$ /home/josevnz/.local/share/uv/python/cpython-3.13.1-linux-x86_64-gnu/bin/python3.13 Python 3.13.1 (main, Jan 14 2025, 22:47:38) [Clang 19.1.6 ] on linux Type "help", "copyright", "credits" or "license" for more information. >>>
Interesting, a custom location that is not in the PATH, that allows you to mix and match Python versions.
Let’s see if uv can re-use installations now. Imagine, now, that I want to install the tool autopep8 (used to correct style issues on Python code) using Python 3.13:
Did the new autopep8 installation re-use the Python3.13 we installed before?
[josevnz@dmaf5 ~]$ which autopep8
~/.local/bin/autopep8
[josevnz@dmaf5 ~]$ head -n 1 ~/.local/bin/autopep8
#!/home/josevnz/.local/share/uv/tools/autopep8/bin/python
[josevnz@dmaf5 ~]$ ls -l /home/josevnz/.local/share/uv/tools/autopep8/bin/python
lrwxrwxrwx. 1 josevnz josevnz 83 Mar 22 16:50 /home/josevnz/.local/share/uv/tools/autopep8/bin/python -> /home/josevnz/.local/share/uv/python/cpython-3.13.1-linux-x86_64-gnu/bin/python3.13
Yes it did, very good, we are not wasting space with duplicate Python interpreter installations.
But what if we want to re-use the existing system python3? If we force the installation, will we have a duplicate (newly downloaded and existing system-wide installation)?
My system has Python 3.11, let’s force the autopep8 install and see what happens:
josevnz@dmaf5 ~]$ uv tool install autopep8 --force --python 3.11 Resolved 2 packages in 3ms Uninstalled 1 package in 1ms Installed 1 package in 3ms ~ autopep8==2.3.2 Installed 1 executable: autopep8
# Where ia autopep8 [josevnz@dmaf5 ~]$ which autopep8 ~/.local/bin/autopep8
# What python is used to run autopep8? Check the Shebang on the script [josevnz@dmaf5 ~]$ head -n 1 ~/.local/bin/autopep8 #!/home/josevnz/.local/share/uv/tools/autopep8/bin/python3
# Where does that Python point to? [josevnz@dmaf5 ~]$ ls -l /home/josevnz/.local/share/uv/tools/autopep8/bin/python3 lrwxrwxrwx. 1 josevnz josevnz 6 Mar 22 16:56 /home/josevnz/.local/share/uv/tools/autopep8/bin/python3 -> python [josevnz@dmaf5 ~]$ ls -l /home/josevnz/.local/share/uv/tools/autopep8/bin/python lrwxrwxrwx. 1 josevnz josevnz 19 Mar 22 16:56 /home/josevnz/.local/share/uv/tools/autopep8/bin/python -> /usr/bin/python3.11
uv is smart enough to use the system Python.
Now say that you want to make this Python3 version the default for your user. There is a way to do that using the experimental flags --preview (add to the PATH location) and --default (make a link to python3):
[josevnz@dmaf5 ~]$ uv python install 3.13 --default --preview
Installed Python 3.13.1 in 23ms
+ cpython-3.13.1-linux-x86_64-gnu (python, python3, python3.13)
# Which one is now python3
[josevnz@dmaf5 ~]$ which python3
~/.local/bin/python3
# Is python3.13 our default python3?
[josevnz@dmaf5 ~]$ which python3.13
~/.local/bin/python3.13
If you want to enforce a more strict control on what interpreters can be installed, you can create a $XDG_CONFIG_DIRS/uv/uv.toml or ~/.config/uv/uv.toml file and you can put the following settings there:
# Location: ~/.config/uv/uv.toml or /etc/uv/uv.toml
# https://docs.astral.sh/uv/reference/settings/#python-preference: only-managed, *managed*, system, only-system
python-preference = "only-system"
# https://docs.astral.sh/uv/reference/settings/#python-downloads: *automatic*, manual or never
python-downloads = "manual"
Now we can call it without using uv or uvx, as long as long as you add ~/.local/bin in your PATH environment variable. You can confirm if that is the case by using which:
which ansible-playbook
~/.local/bin/ansible-playbook
Another advantage of using ‘tool install‘ is that if the installation is big (like Ansible), or you have a slow network connection, you only need to install once, since it is cached locally and ready for use the next time.
The last trick for this section, is if you installed several Python tools using uv, you can upgrade them all in one shot with the --upgrade flag:
We have seen, so far, how to manage someone else’s packages, what about our own? The next section explores that.
Managing your Python projects with UV
Eventually, you will find yourself packaging a Python project that has multiple modules, scripts and data files. Python offers a rich ecosystem to manage this scenario and uv takes away some of the complexity.
Our small demo project will create an application that will use the ‘Grocery Stores‘ data from the Connecticut Data portal. The data file is updated every week and is in JSON format. The application takes that data and displays it in a terminal as a table.
‘Uv init‘ allows me to initialize a basic project structure, which we will improve on shortly. I always like to start a project with a description and a name:
[josevnz@dmaf5]$ uv init --description 'Grocery Stores in Connecticut' grocery_stores Initialized project `grocery_stores` at `/home/josevnz/tutorials/docs/Enhancing_Your_Python_Workflow_with_UV_on_Fedora/grocery_stores`
uv created a few files here:
[josevnz@dmaf5 Enhancing_Your_Python_Workflow_with_UV_on_Fedora]$ ls -a grocery_stores/
. .. hello.py pyproject.toml .python-version README.md
The most important part, for now, is pyproject.toml. It has a full description of your project among other things:
[project]
name = "pretty-csv"
version = "0.1.0"
description = "Grocery Stores in Connecticut"
readme = "README.md"
requires-python = ">=3.13"
dependencies = []
Also created is .python-version which has the version of Python supported by this project. This is how uv enforces the Python version used in this project.
Another file is hello.py. You can get rid of it, it has a hello world in Python. We will also later fill the README.md with proper content.
Back to our script, we will use a TUI framework called Textual that will allow us to take the JSON file and show the contents as a table. Because we know that dependency, let’s use uv to add it to our project:
We downloaded textual and their transitive dependencies
pyproject.toml was updated and now the dependencies section has values (go ahead and open the file) and see:
[project]
name = "pretty-csv"
version = "0.1.0"
description = "Simple program that shows contents of a CSV file as a table on the terminal"
readme = "README.md"
requires-python = ">=3.13"
dependencies = [
"textual==2.1.2",
]
uv created a uv.lock file next to the pyproject.toml. This file has the exact version of all the packages used in your project, which ensures consistency.
You can see uv.lock is very explicit, as its purpose is to be as specific and unambiguous as possible. This file is meant to be added to your repository on git, same as ‘.python-version’ . It will allow developers across your team to have a consistent tool set installed.
Let’s also add the ‘httpx‘ library, so we can download the grocery data asynchronously:
These are runtime dependencies, but what if we want to use tools to do things like linting, or profiling? We will explore that in the next section.
Development dependencies
You may want to use some tools while developing your application, like pytest to run unit tests or pylint to check the correctness of the code. But you don’t want to deploy those tools in your final version of the application.
This is a development dependency, and you can add them to a special ‘–dev‘ section of your project like this :
This produces the following section on my pyproject.toml file:
[dependency-groups]
dev = [
"pylint==3.3.6",
"pytest==8.3.5",
]
Writing a JSON-to-Table display Python application
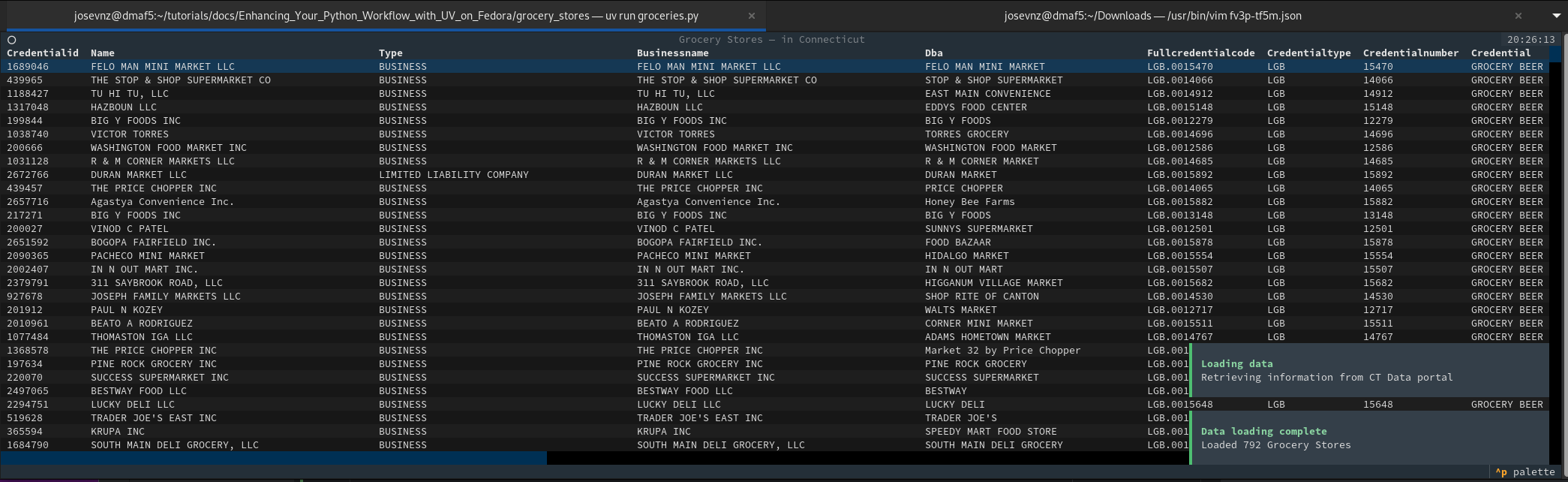
The first step is to have the code that loads the data, then renders the Grocery store raw data as a table. I will let you read the Textual tutorial on how to do this and instead will share the bulk of the code I wrote in a file called ‘groceries.py‘:
"""
Displays the latest Grocery Store data from
the Connecticut Data portal.
Author: Jose Vicente Nunez <kodegeek.com@protonmail.com>
Press ctrl+q to exit the application.
"""
import httpx
from httpx import HTTPStatusError
from textual.app import App, ComposeResult
from textual.widgets import DataTable, Header, Footer
from textual import work, on
from orjson import loads
GROCERY_API_URL = "https://data.ct.gov/resource/fv3p-tf5m.json"
class GroceryStoreApp(App):
def compose(self) -> ComposeResult:
header = Header(show_clock=True)
yield header
table = DataTable(id="grocery_store_table")
yield table
yield Footer()
@work(exclusive=True)
async def update_grocery_data(self) -> None:
"""
Update the Grocery data table and provide some feedback to the user
:return:
"""
table = self.query_one("#grocery_store_table", DataTable)
async with httpx.AsyncClient() as client:
response = await client.get(GROCERY_API_URL)
try:
response.raise_for_status()
groceries_data = loads(response.text)
table.add_columns(*[key.title() for key in groceries_data[0].keys()])
cnt = 0
for row in groceries_data[1:]:
table.add_row(*(row.values()))
cnt += 1
table.loading = False
self.notify(
message=f"Loaded {cnt} Grocery Stores",
title="Data loading complete",
severity="information"
)
except HTTPStatusError:
self.notify(
message=f"HTTP code={response.status_code}, message={response.text}",
title="Could not download grocery data",
severity="error"
)
def on_mount(self) -> None:
"""
Render the initial component status, show an initial loading message
:return:
"""
table = self.query_one("#grocery_store_table", DataTable)
table.zebra_stripes = True
table.cursor_type = "row"
table.loading = True
self.notify(
message=f"Retrieving information from CT Data portal",
title="Loading data",
severity="information",
timeout=5
)
self.update_grocery_data()
@on(DataTable.HeaderSelected)
def on_header_clicked(self, event: DataTable.HeaderSelected):
"""
Sort rows by column header
"""
table = event.data_table
table.sort(event.column_key)
if __name__ == "__main__":
app = GroceryStoreApp()
app.title = "Grocery Stores"
app.sub_title = "in Connecticut"
app.run()
Now that we have some code, let’s test it. First using an editable mode (in a way similar to using pip):
My test code just simulates starting the application and pressing ctrl-q to exit it. Not very useful but this next test gives you an idea what you can to do to test your application simulating keystrokes:
"""
Unit tests for Groceries application
https://textual.textualize.io/guide/testing/
"""
import pytest
from grocery_stores_ct.groceries import GroceryStoreApp
@pytest.mark.asyncio
async def test_groceries_app():
groceries_app = GroceryStoreApp()
async with groceries_app.run_test() as pilot:
await pilot.press("ctrl+q") # Quit
Now run the tests:
[josevnz@dmaf5 grocery_stores]$ uv run --dev pytest test_groceries.py
================================================= 1 passed in 1.17s ==================================================
Packaging and uploading to your Artifact repository
It is time to package our new application. Let’s try to build it:
[josevnz@dmaf5 grocery_stores]$ uv build
Building source distribution...
error: Multiple top-level modules discovered in a flat-layout: ['groceries', 'test_groceries'].
To avoid accidental inclusion of unwanted files or directories,
setuptools will not proceed with this build.
...
Not so fast. uv is getting confused as we have 2 main modules, instead of one. The right thing to do is to setup a src-layout for our project, so we move some files around.
After moving groceries.py to a module called ‘src/grocery_stores_ct’ and tests_groceries to test:
uv pip install --editable .[dev]
uv run --dev pytest test/test_groceries.py
uv run --with 'pylint==3.3.6' pylint src/grocery_stores_ct/groceries.py
And now build it again:
[josevnz@dmaf5 grocery_stores]$ uv build
Building source distribution...
running egg_info
writing src/grocery_stores.egg-info/PKG-INFO
writing dependency_links to src/grocery_stores.egg-info/dependency_links.txt
removing build/bdist.linux-x86_64/wheel
Successfully built dist/grocery_stores-0.1.0.tar.gz
Successfully built dist/grocery_stores-0.1.0-py3-none-any.whl
Now comes the time when you want to share your application with others.
Uploading to a custom index
I don’t want to pollute the real pypi.org with a test application, so instead I will set my index to be something else, like test.pypi.org. In your case this can be a Nexus 3 repository, an Artifactory repository, or whatever artifact repository you have set up in your company.
For pypi, add the following to your pyproject.toml file:
# URL match your desired location
[[tool.uv.index]]
name = "testpypi"
url = "https://test.pypi.org/simple/"
publish-url = "https://test.pypi.org/legacy/"
explicit = true
You will also need to generate an application token (this varies by provider and won’t be covered here). Once you get your token, call uv publish --index testpypi $token:
[josevnz@dmaf5 grocery_stores]$ uv publish --index testpypi --token pypi-AgENdGVzdC5weXBpLm9yZwIkYzFkODg5ODMtODUxZS00ODc2LWFhYzMtZjhhNWFmNjZhODJmAAIqWzMsIjZmZGNjMzc1LTYxNmEtNDA5Zi1hNTJkLWJhMDZmNWQ3N2NlZSJdAAAGIG3wrTZdgmOBlahBlahBlah
warning: `uv publish` is experimental and may change without warning
Publishing 2 files https://test.pypi.org/legacy/
Uploading grocery_stores-0.1.0-py3-none-any.whl (2.7KiB)
Uploading grocery_stores-0.1.0.tar.gz (2.5KiB)
Other things that you should have on your pyproject.toml
UV does a lot of things but doesn’t do everything. There is a lot of extra Metadata that you should have on your pyproject.toml file. I’ll share some of the essentials here:
If you do not want a project to be uploaded to Pypi by accident, add the following classifier: ‘Private :: Do Not Upload‘.
You will need to bump the version, rebuild and upload again after making any changes, like adding keywords (useful to tell the world where to find your app).
These 8 lines at the begining of the script indicates that this is the embedded metadata.
If you remember our pyproject.toml file, these are the instructions used by package managers like setuptools and uv to handle the project dependencies, like python versions and required libraries to run. This is powerful, since tools capable of reading this inline metadata (between the `///` sections) do not need to check an extra file.
Now, uv (has a flag) called `–script` which allows it to interpret the inline metadata on the script. For example, this will update the dependencies for the `example` script, by reading them from the script directly:
uv add --script example.py 'requests<3' 'rich' uv run example.py
This is convenient. If we combine both inline dependencies and uv we can have a self executable script that can also download its own dependencies:
#!/usr/bin/env -S uv run --script # /// script # requires-python = ">=3.13" # dependencies = [ # "httpx==0.28.1", # "orjson==3.10.15", # "textual==2.1.2", # ] # /// """ Displays the latest Grocery Store data from the Connecticut Data portal. Author: Jose Vicente Nunez <kodegeek.com@protonmail.com> This version of the script uses inline script metadata: https://packaging.python.org/en/latest/specifications/inline-script-metadata/ Press ctrl+q to exit the application. """
import httpx from httpx import HTTPStatusError from textual.app import App, ComposeResult from textual.widgets import DataTable, Header, Footer from textual import work, on # pylint: disable=no-name-in-module from orjson import loads
@work(exclusive=True) async def update_grocery_data(self) -> None: """ Update the Grocery data table and provide some feedback to the user :return: """ table = self.query_one("#grocery_store_table", DataTable)
async with httpx.AsyncClient() as client: response = await client.get(GROCERY_API_URL) try: response.raise_for_status() groceries_data = loads(response.text) table.add_columns(*[key.title() for key in groceries_data[0].keys()]) cnt = 0 for row in groceries_data[1:]: table.add_row(*(row.values())) cnt += 1 table.loading = False self.notify( message=f"Loaded {cnt} Grocery Stores", title="Data loading complete", severity="information" ) except HTTPStatusError: self.notify( message=f"HTTP code={response.status_code}, message={response.text}", title="Could not download grocery data", severity="error" )
def on_mount(self) -> None: """ Render the initial component status :return: """ table = self.query_one("#grocery_store_table", DataTable) table.zebra_stripes = True table.cursor_type = "row" table.loading = True self.notify( message="Retrieving information from CT Data portal", title="Loading data", severity="information", timeout=5 ) self.update_grocery_data()
def sort_reverse(self, sort_type: str): """ Determine if `sort_type` is ascending or descending. """ reverse = sort_type in self.current_sorts if reverse: self.current_sorts.remove(sort_type) else: self.current_sorts.add(sort_type) return reverse
if __name__ == "__main__": app = GroceryStoreApp() app.title = "Grocery Stores" app.sub_title = "in Connecticut" app.run()
This is the same script we wrote before, except that we use the last big of magic here:
!/usr/bin/env -S uv run --script
We call env (part of coreutils) to split arguments (-S) to call uv with the --script flag. Then uv reads the inline metadata and downloads the required python with all the dependencies automatically:
[josevnz@dmaf5 Enhancing_Your_Python_Workflow_with_UV_on_Fedora]$ chmod a+xr inline_script_metadata/groceries.py [josevnz@dmaf5 Enhancing_Your_Python_Workflow_with_UV_on_Fedora]$ ./inline_script_metadata/groceries.py Installed 18 packages in 29ms # And here the script starts running!!!
It doesn’t get simpler than this. This is great, for example, to run installer scripts.
Learning more
A lot of material is covered here but there is still more to learn. As with everything, you will need to try to see what better fits your style and available resources.
Below is a list of links I found useful and may also help you:
The official uv documentation is very complete, and you will most likely spend your time going back and forth reading it.
Users of older Fedora distributions may take a look at the UV Source RPM. Lots of good stuff, including Bash auto-completion for UV.
Anaconda and miniconda also have counter parties written in rust (mamba and micromamba), in case you decide jumping to uv is too soon. These are backward compatible and much faster.
Did you remember the file uv.lock we discussed before? Now Python has agreed to a way to manage dependencies (PEP 751) in a much more powerful way than the pip requirements.txt file. Keep an eye on packaging.python.org for more details.
I showed you how to use pylint to check for code smells. I would strongly recommend you try ruff. It is written in rust and it is pretty fast:
[josevnz@dmaf5 grocery_stores]$ uv tool install ruff@latest Resolved 1 package in 255ms Prepared 1 package in 1.34s Installed 1 package in 4ms ruff==0.11.2 Installed 1 executable: ruff # The lets check the code [josevnz@dmaf5 grocery_stores]$ ruff check src/grocery_stores_ct All checks passed!
Remember: “perfect is the enemy of good”, so try uv and other tools and see what is best for your Python workflow needs.
Last week, I posted about running nightly syslog-ng container images on arm64. However, you can also install syslog-ng directly on the host (in my case, a Raspberry Pi 3), running the latest Raspberry OS.
Important projects for getting Windows applications up and running on Linux
Let's find out why we need another game launcher for Linux and why famous developers invest their time to create it. The first question from newcomers will probably be "What does the word UMU even mean? UMU comes from Polynesian culture and means hot volcanic stones that are good for cooking. So this project is definitely hot.
Linux as a platform for games is very promising - Valve, CodeWeavers (founders of Wine, the most important application for running Windows software on Linux) and other companies and developers have invested a lot in the ability to run Windows applications and Linux graphics stack. And this is not only about games - Wine is able to run Adobe Suite (Photoshop, Illustrator, InDesign), Microsoft Office and many other applications.
The Steam storefront
For the average Linux user, there is a landscape of tools that make life easier:
Wine, developed by CodeWeavers and the open source community.
Proton - a fork of Wine, created by Valve and also developed with the help of the open source community.
At first sight, these two projects are competitors, but this is not true. Both have the same root and success of one is also success of the other, so cooperation is profitable for both.
Additional tools:
DXVK - Vulkan-based implementation of D3D8, 9, 10 and 11 for Linux and Wine.
VK3D - is a 3D graphics library based on Vulkan with an API very similar to Direct3D 12.
VKD3D-proton - VK3D fork from Valve
winetricks - an easy way to work around problems in Wine
protontricks - wrapper that does Winetricks things for Proton-enabled games, also requires Winetricks.
Finally, the peak of the iceberg - game launchers:
Lutris
PlayOnLinux
Bottles
Heroic Games Launcher
Faugus Launcher and many more.
There are a lot of launchers - everyone wants to make life easier for their users. Steam is a launcher too, with the store, community, achievements and a lot of stuff inside. Two negative Steam moments - it's a proprietary 32-bit application. Why open source is better than proprietary is obvious - you can improve it and analyze possible security issues. 32-bit application is painful for Linux maintainers because they have to provide additional 32-bit libraries as dependencies, update them and do QA.
So can we use Proton without Steam for a more open source gaming environment? Short answer - yes, but not without problems. Proton is developed with full Steam compatibility and uses Steam Runtime - this is a compatible environment for running Steam games on various Linux distributions. Here UMU wins advanced score because it is nothing else than modified Steam Runtime Tools and Steam Linux Runtime that Valve uses for Proton.
More competition is always better for customers, so more game launchers will bring more unique features to the Linux ecosystem. Some launchers already support UMU: Lutris, Heroic Games Launcher or Faugus Launcher. Also, UMU works inside Snap or Flatpak packages, but doesn't provide it's own package for both yet.
Who stays behind of UMU
UMU was created by important figures from Linux gaming scene:
GloriousEggroll - main contributor of Nobara Linux, proton-ge, wine-ge.
They have very different levels of commitment, but just the fact that they are all involved sends a good signal to all of us.
Go hard or go home - how UMU can win the game
Many years ago, when I first tried Wine to run a game on Linux, the algorithm was this:
Install Wine and run wine game.exe.
If it doesn't work, analyze the log and use winetricks to install the correct library.
If it fails, go to the Wine Application Database also called AppDB to find the right way.
UMU is well designed by people with the above experience, so they decided to create UMU Database, which contains all the information needed to run games successfully. There are also differences between game versions: games from Steam and Epic Games Store are not exactly the same and may need different fixes for successful gameplay. The UMU game fixes are called protonfixes and their repository can be found here.
For example, let's search for Grand Theft Auto V in the UMU database. This is the very popular game that doesn't need any advertising:
TITLE,STORE,CODENAME,UMU_ID,COMMON ACRONYM (Optional),NOTE (Optional)
Grand Theft Auto V,egs,9d2d0eb64d5c44529cece33fe2a46482,umu-271590,gtav,
Grand Theft Auto V,none,none,umu-271590,gtav,Standalone Rockstar installer
Grand Theft Auto V Enhanced on Steam
As you can see this is the same game with id umu-271590 but from different stores: Epic Games and Rockstar. Currently the UMU database has 1090 games, this is a good result because the first UMU release was in February 2024.
Non-Steam Games
First you need to install Proton. You can do it using Steam or in case of Proton GE use it's README. You don't need to worry about the Steam Runtime, the latest version will be downloaded to $HOME/.local/share/umu.
Now start with no options:
$ umu-run game.exe
UMU will automatically set Proton and create a Wine prefix. It will work in some cases, but many games will need more tuning. The next command will run Star Citizen, apply protonfix and create Wine prefix in a different location:
If you want to run native Linux game and disable Proton there's special option for it:
UMU_NO_PROTON=1 umu-run game.sh
Steam Games
They are supported - run games from any store just like you do on Steam. The main difference from doing it manually with Wine or Proton is that UMU can automatically apply Proton fixes to the game title. When Steam runs a game through Proton, it shares some data about specific game title and personal configuration that title needs - for example, does it need OpenGL or Vulkan. UMU is able to talk to Proton in the same way Steam does.
Final Note
Unsplash / Uriel Soberanes
UMU is the unified launcher for Linux that allows you to run Windows games outside of Steam and does the heavy lifting of setting up the game environment correctly. It has a large database of games with preconfigured protonfixes for each, but also supports many flags and environment variables for complex configurations. You can use UMU as a standalone launcher or together with other launchers like Lutris to get a stable Proton environment for many games. Thank the contributors and remember - you can win even faster with open source software!
We did another mass update/reboot cycle. We try and do these every so often,
as the fedora release schedule permits. We usually do all our staging hosts
on a monday, on tuesday a bunch of hosts that we can reboot without anyone
really noticing (ie, we have HA/failover/other paths or the service is just
something that we consume, like backups), and finally on wednsday we do
everything else (hosts that do cause outages).
Things went pretty smoothly this time, I had several folks helping out this
time and thats really nice. I have done them all by myself, but it takes a while.
We also fixed a number of minor issues with hosts: serial consoles not working right
and nbde not running correctly and also zabbix users being setup correctly locally.
There was also a hosted server where reverse dns was wrong, causing ansible to
have the wrong fqdn and messing up our update/reboot playbook.
Thanks James, Greg and Pedro!
I also used this outage to upgrade our proxies from Fedora 40 to Fedora 41.
After that our distribution of instances is:
number / ansible_distribution_version
252 41
105 9.5
21 8.10
8 40
2 9
1 43
It's interesting that we now have 2.5x as many Fedora instances as RHEL.
Although thats mostly the case due to all the builders being Fedora.
The Fedora 40 GA compose breakage
Last week we got very low on space on our main fedora_koji volume.
This was mostly caused by the storage folks syncing all the content
to the new datacenter, which meant that it kept snapshots as it
was syncing.
In an effort to free space (before I found out there was nothing we
could do but wait) I removed an old composes/40/ compose. This was the
final compose for Fedora 40 before it was released and the reason in
the past that we kept it was to allow us to make delta rpms more easily.
It's the same content as the base GA stuff, but it's in one place instead
of split between fedora and fedora-secondary trees. Unfortunately,
there were some other folks using this. Internally they were using it
for some things and iot also was using it to make their daily image updates.
Fortunately, I didn't actually fully delete it, I just copied it to
an archive volume, so I was able to just point the old location
to the archive and everyone should be happy now.
Just goes to show you if you setup something for yourself, often
unknown to you others find it helpfull as well, so retiring things
is hard. :(
New pagure.io DDoS
For the most part we are handling load ok now on pagure.io. I think
this is mostly due to us adding a bunch of resources, tuning things
to handle higher load and blocking some larger abusers.
However, on friday we got a new fun one: A number of ip's were crawling
an old (large) git repo grabbing git blame on ever rev of every file.
This wasn't causing a problem on the webserver or bandwith side,
but instead causing problems for the database/git workers. Since
they had to query the db on every one of those and get a bunch
of old historical data, it saturated the cpus pretty handily.
I blocked access to that old repo (thats not even used anymore)
and that seemed to be that, but they may come back again doing the
same thing. :(
We do have a investigation open for what we want to do long term.
We are looking at anubis, rate limiting, mod_qos and other options.
I really suspect these folks are just gathering content which they
plan to resell to AI companies for training. Then the AI company
can just say they bought it from bobs scraping service and 'openwash'
the issues. No proof of course, but just a suspicion.
Final freeze coming up
Finally the final freeze for Fedora 42 starts next tuesday,
so we have been trying to land anything last minute.
If you're a maintainer or contributor working on Fedora 42,
do make sure you get everthing lined up before the freeze!
On this day in 1943 Vangelis was born. The very first CD I bought over three decades ago was composed by him: Chariots of Fire. After so many years, I still love his music.
My Vangelis collection
As you can see, I do not have everything by him. I do not like his earliest and latest works that much, but almost everything in between. Unfortunately I could not find everything on CD. For example, I loved “Soil Festivities”, especially since I was a soil engineer during my college years. But not only is it not available on CD (even used), it is also missing from streaming services.
Several times I learned years later that the music I was listening to was actually a movie soundtrack. Chariots of Fire is one of them, as well as Blade Runner. It became one of my favorite movies, and it’s the only movie I have on 4K bluray.
I’m listening to Vangelis right now and expect to listen to a few more of his albums today :-)
For the last few months, one of the things I’ve been working on in Fedora is
adding support for SecureBoot on Arm64. The details of that work will be the
subject of a later post, but as part of this work I’ve become somewhat familiar
with the signing infrastructure in Fedora and how it works. This post
introduces the various pieces of the current infrastructure, and how they fit
together.
Signed?
Pretty much anything Fedora produces and distributes is digitally signed so
users can verify it did, in fact, come from the Fedora project. Perhaps the
most obvious example of this is the RPM packages Fedora produces. However,
plenty of other artifacts are also signed, like OSTree commits.
Signing works using public-key
cryptography. We have the
private key that we need to keep secret, and we distribute the public keys to
users so they can verify the artifact.
Robosignatory
Signing is (mostly) an automated process. A service, called
robosignatory, connects to an AMQP
message broker and subscribes to several message topics. When an artifact is
created that needs signing, the creator of the artifact sends a message to the
AMQP broker using one of these topics.
Robosignatory does not sign artifacts itself. It collects requests from various
other services and submits them to the signing server on behalf of those
systems. The signing server is the system that contains and protects the
private keys.
Sigul
Sigul is the signing server that holds the private
keys and performs signing operations. It is composed of three parts: the
client, the bridge, and the server.
The Server
The Sigul server is designed to control access to signing keys and to provide a
minimal attack surface. It does not behave like a traditional server in that it
does not accept incoming network connections. Instead, it connects to the Sigul
bridge, and the bridge forwards requests to it via that connection.
This allows the firewall to be configured to allow outgoing traffic to a single
host, and to block all incoming connections. This does mean that the host
cannot be managed via normal SSH operations. Instead this is done in Fedora via
the host’s out-of-band management console.
Private keys are encrypted on disk. When users are granted access to keys, the
key is encrypted for that particular user.
The Bridge
The Sigul bridge acts as a specialized proxy. Both the client and server connect
to the bridge, and it forwards requests and responses between them.
Unlike the typical proxy, the Sigul bridge does a few interesting things.
Firstly, it requires the client to authenticate via TLS certificates. The
client then sends the bridge the request it wishes to make. The bridge forwards
that request to the server. The bridge then expects the client and server to
send an arbitrary amount of data to each other. This arbitrary data is framed
as chunks and it forwards that data back and forth until an end of stream
signal is sent by the server and client.
Finally, it forwards the server’s response to the client.
The Client
The client is a command-line interface that sends requests to the server via
the bridge. This client can be used to create users and keys, grant and revoke
access to keys, and request signatures in various formats. Robosignatory
invokes the CLI to sign artifacts.
The client connects to the bridge as described above. After authenticating with
the bridge and sending the request, it begins a second TLS connection
configured with the Sigul server’s hostname, and sends and receives data on
this connection over the TLS connection it has with the Sigul bridge. It relies
on this inner TLS connection to send a set of session keys to the server
without the bridge being able to intercept them. These session keys are used to
sign the Sigul server’s responses so the client can be sure the bridge did not
tamper with them.
After it has established a set of secrets with the server, the remainder of the
interaction occurs over the TLS connection with the bridge, but since the
responses are signed both the client and server can be confident the bridge has
not tampered with the conversation.
Conclusion
It’s an interesting setup, and has served Fedora for many years. There is
plenty of code in Sigul which dates back to 2009, not long after Python 2.6 was
released with exciting new features like the standard library json module. It
was likely developed for RHEL 5 which means Python 2.4.
Unfortunately, at least one of the libraries (python-nss) it depends on to work
are not maintained and not in Fedora 42, so something will have to be done in
the near future. Still, it’s not ready to sign off just yet.
“What? A MacBook Air cheaper than a Windows laptop? Impossible!”
Well, if you look in the Wintel (Windows + Intel) universe for a laptop with the same features as Apple’s entry-level laptop — the MacBook Air — the Wintel version will be more expensive.
A basic laptop today should have a 3K or 4K display (Full HD is already obsolete), solid-state storage, high-quality camera, microphone, and audio, and be thin, lightweight, and stylish. Most importantly, the battery should last all day. This last feature is not possible in Intel-based laptops, where, in practice, the battery lasts no more than 90 minutes. A modern laptop is used like a smartphone: unplugged from the outlet, carried around all day, and recharged while you have lunch or sleep.
So yes, you can find cheaper laptops, but they will have worse features than the minimum standard. They also use lower-quality components (camera, microphone, display) and outdated technology (storage, CPU).
This is a weekly report from the I&R (Infrastructure & Release Engineering) Team. We provide you both infographic and text version of the weekly report. If you just want to quickly look at what we did, just look at the infographic. If you are interested in more in depth details look below the infographic.
Week: 24 Mar – 28 Mar 2025
Infrastructure & Release Engineering
The purpose of this team is to take care of day to day business regarding CentOS and Fedora Infrastructure and Fedora release engineering work. It’s responsible for services running in Fedora and CentOS infrastructure and preparing things for the new Fedora release (mirrors, mass branching, new namespaces etc.). List of planned/in-progress issues
Fedora test days are events where anyone can help make certain that changes in Fedora Linux work well in an upcoming release. Fedora community members often participate, and the public is welcome at these events. If you’ve never contributed to Fedora before, this is a perfect way to get started.
There are three test periods occurring in the coming days:
Monday March 31 through April 7, is to test the KDE Desktop and Apps
Wednesday April 2 through April 6, is to test Upgrade Test Days
Saturday April 5 through April 7, is to test Virtualization
Come and test with us to make Fedora 42 even better. Read more below on how to do it.
KDE Plasma and Apps
The KDE SIG is working on final integration for Fedora 42. Some of the app versions were recently released and will soon arrive in Fedora Linux 42. As a result, the KDE SIG and QA teams have organized a test week from Monday, March 31, 2025, through Monday, April 07, 2025. The wiki page contains links to the test images you’ll need to participate.
Upgrade test day
As we approach the Fedora Linux 42 release date, it’s time to test upgrades. This release has many changes, and it becomes essential that we test the graphical upgrade methods as well as the command-line methods.
This test period will run from Wednesday, April 2 through Sunday, April 6. It will test upgrading from a fully updated F40 or F41 to F42 for all architectures (x86_64, ARM, aarch64) and variants (WS, cloud, server, silverblue, IoT). See this wiki page for information and details. For this test period, we also want to test DNF5 Plugins before and after upgrade. Recently noted regressions resulted in a Blocker Bug. The DNF5 Plugin details are available here.
Virtualization test day
This test period will run from Saturday, April 5 through Monday, April 7 and will test all forms of virtualization possible in Fedora 42. The test period will focus on testing Fedora Linux, or your favorite distro, inside a bare metal implementation of Fedora Linux running Boxes, KVM, VirtualBox and whatever you have. The test cases outline the general features of installing the OS and working with it. These cases are available on the results page.
How do test days work?
A test period is an event where anyone can help make certain that changes in Fedora work well in an upcoming release. Fedora community members often participate, and the public is welcome at these events. Test days are the perfect way to start contributing if you not in the past.
The only requirement to get started is the ability to download test materials (which include some large files) and then read and follow directions step by step.
Detailed information about all the test days are on the wiki page links provided above. If you are available on or around the days of the events, please do some testing and report your results
Release Candidate versions are available in the testing repository for Fedora and Enterprise Linux (RHEL / CentOS / Alma / Rocky and other clones) to allow more people to test them. They are available as Software Collections, for parallel installation, the perfect solution for such tests, and as base packages.
RPMs of PHP version 8.4.6RC1 are available
as base packages in the remi-modular-test for Fedora 40-42 and Enterprise Linux≥ 8
as SCL in remi-test repository
RPMs of PHP version 8.3.20RC1 are available
as base packages in the remi-modular-test for Fedora 40-42 and Enterprise Linux≥ 8
as SCL in remi-test repository
ℹ️ The packages are available for x86_64 and aarch64.
ℹ️ PHP version 8.2 is now in security mode only, so no more RC will be released.
The Fedora Infrastructure Team is announcing the end of OpenID in Fedora Account System (FAS). This will occur on 20th May 2025.
Why the change?
OpenID is being replaced by OpenIDConnect (OIDC) in most of the modern web and most of the Fedora infrastructure is already using OIDC as the default authentication method. OIDC offers better security by handling both authentication and authorization. It also allows us to have more control over services that are using Fedora Account System (FAS) for authentication.
What will change for you?
With the End Of Life of OpenID we will switch to OIDC for everything and no longer support authentication with OpenID.
If your web or service is already using OIDC for authentication nothing will change for you. If you are still using OpenID open a ticket on Fedora Infrastructure issue tracker and we will help you with migration to OIDC.
For users using FAS as authentication option there should be no change at all.
How to check if a service you maintain is using OpenID?
You may quickly check if your service is using OpenID for FAS authentication by looking at where you are redirected when logging in with FAS.
We will be reaching out directly to services we identify as using OpenID. But since we don’t have control over OpenID authentication, we can’t identify everyone.
If you are interested in following this work feel free to watch this ticket.
Last December, the CD shop where I bought most of my collection closed its doors for good. I had seen it coming — the owner had been gradually winding down the business in preparation for retirement — but after nearly 30 years of shopping there, it was still a tough moment.
Stereo logo
This logo belongs to Periferic Records - Stereo Kft.. Back in the nineties, during my university years, I used to look for this logo at concerts, always hoping to spot a bearded man selling an incredible selection of CDs. Imagine my surprise when, in 2002, I attended a concert and discovered that the organizer was none other than that same bearded man — who also happened to be one of my second cousins!
From that moment on, I became a regular at the shop. The owner was a publisher of some of my favorite music, including Hungarian progrock and piano albums. Some standout names: After Crying, Vedres Csaba, and Solaris. While the shop specialized in progrock — with a selection unlike anywhere else — it also offered a wide variety of other genres.
When I received my first big paycheck, I went straight to the store and bought dozens of CDs. Today, streaming services like TIDAL and Spotify have recommendation engines, but back then, nothing could beat the personalized recommendations from the shop’s staff. More than once, I walked out with a free CD as a bonus, one of which became an all-time favorite: Townscream – Nagyvárosi Ikonok.
Unlike many music shops that play background music on low-quality systems, Stereo had StandArt speakers from Heed Audio. These speakers, almost as old as the shop itself, created an immersive listening experience. Though I often rushed in just to pick up an order, on the rare occasion that I had time, I would linger to listen — sometimes discovering new music to take home.
The website still exists, and you can get an ever shorter list of available CD titles by e-mail. In December, I spent most of my free time going through their list of albums, listening to samples on TIDAL and YouTube — nearly 1,500 albums in total. Through this process, I found some rare gems, including one CD I bought purely for its intriguing title: God-Sex-Money. Well, actually the description, “Recommended for Wakeman/Emerson fans,” sealed the deal :-)
Even now, whenever I’m near the old shop, I instinctively start walking toward it — only to remember that an important part of my life is gone forever. But it lives on in my CD collection and my memories.










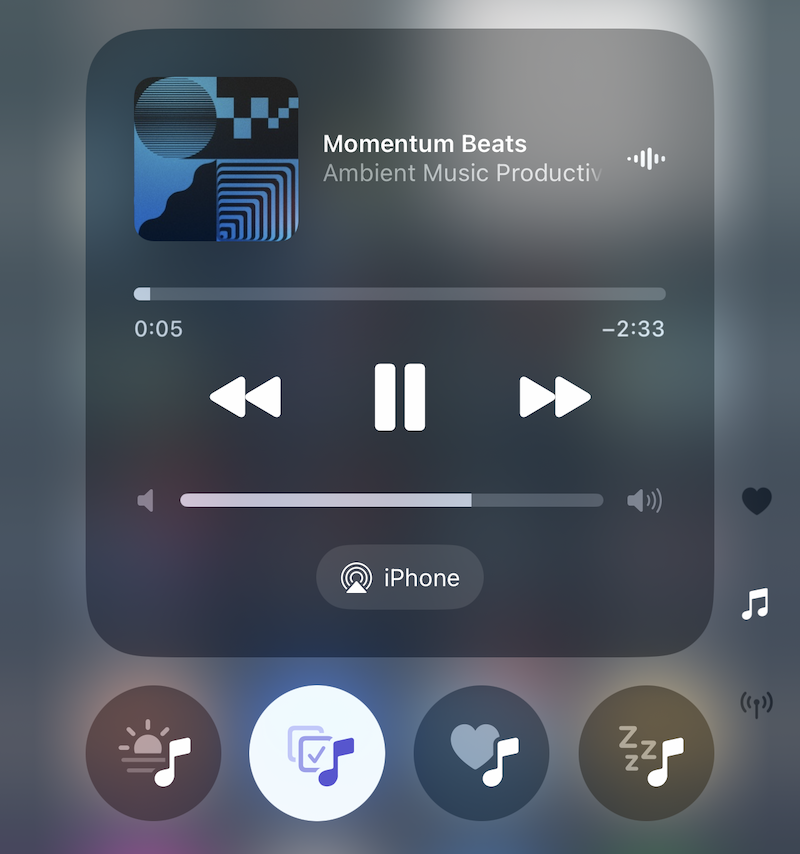
 Control Center that provide endless ambient music in four styles and for four purposes:
Control Center that provide endless ambient music in four styles and for four purposes: Relaxation
Relaxation Focus & Productivity
Focus & Productivity Well-being
Well-being Sleep
Sleep













comments? additions? reactions?
As always, comment on mastodon: https://fosstodon.org/@nirik/114286697832557392